About¶
What is unblob?¶
unblob is an accurate, fast, and easy-to-use extraction suite. It parses unknown binary blobs for more than 30 different archive, compression, and file-system formats, extracts their content recursively, and carves out unknown chunks that have not been accounted for.
unblob is free to use, licensed under MIT license, it has a command line interface and can be used as a Python library. This turns unblob into the perfect companion for extracting, analyzing, and reverse engineering firmware images.
unblob was originally developed and currently maintained by ONEKEY and it is used in production in our ONEKEY analysis platform.
Demo¶

Why unblob?¶
One of the major challenges of embedded security analysis is the sound and safe extraction of arbitrary firmware.
Specialized tools that can extract information from those firmware images already exist, but we were carving for something smarter that could identify both start-offset and end-offset of a specific chunk (e.g. filesystem, compression stream, archive, ...) as well as handle formats split across multiple files.
We stick to the format standard as much as possible when deriving these offsets, and we clearly define what we want out of identified chunks (e.g., not extracting meta-data to disk, padding removal). This strategy helps us feed known valid data to extractors and precisely identify chunks, turning unknown unknowns into known unknowns.
Given the modular design of unblob and the ever-expanding repository of supported formats, unblob could very well be used in areas outside embedded security such as data recovery, memory forensics, or malware analysis.
Our Objectives¶
unblob has been developed with the following objectives in mind:
-
Accuracy - chunk start offsets are identified using battle tested rules, while end offsets are computed according to the format's standard without deviating from it. We minimize false positives as much as possible by validating header structures and discarding overlapping chunks.
-
Security - unblob does not require elevated privileges to run. It's heavily tested and has been fuzz tested against a large corpus of files and firmware images. We rely on up-to-date third party dependencies that are locked to limit potential supply chain issues. We use safe extractors that we audited and fixed where required (see path traversal in ubi_reader, path traversal in jefferson, integer overflow in Yara).
-
Extensibility - unblob exposes an API that can be used to write custom format handlers and extractors in no time.
-
Speed - we want unblob to be blazing fast, that's why we use multi-processing by default, make sure to write efficient code, use memory-mapped files, and use Hyperscan as a high-performance matching library. Computation-intensive functions are written in Rust and called from Python using specific bindings.
How does it work?¶
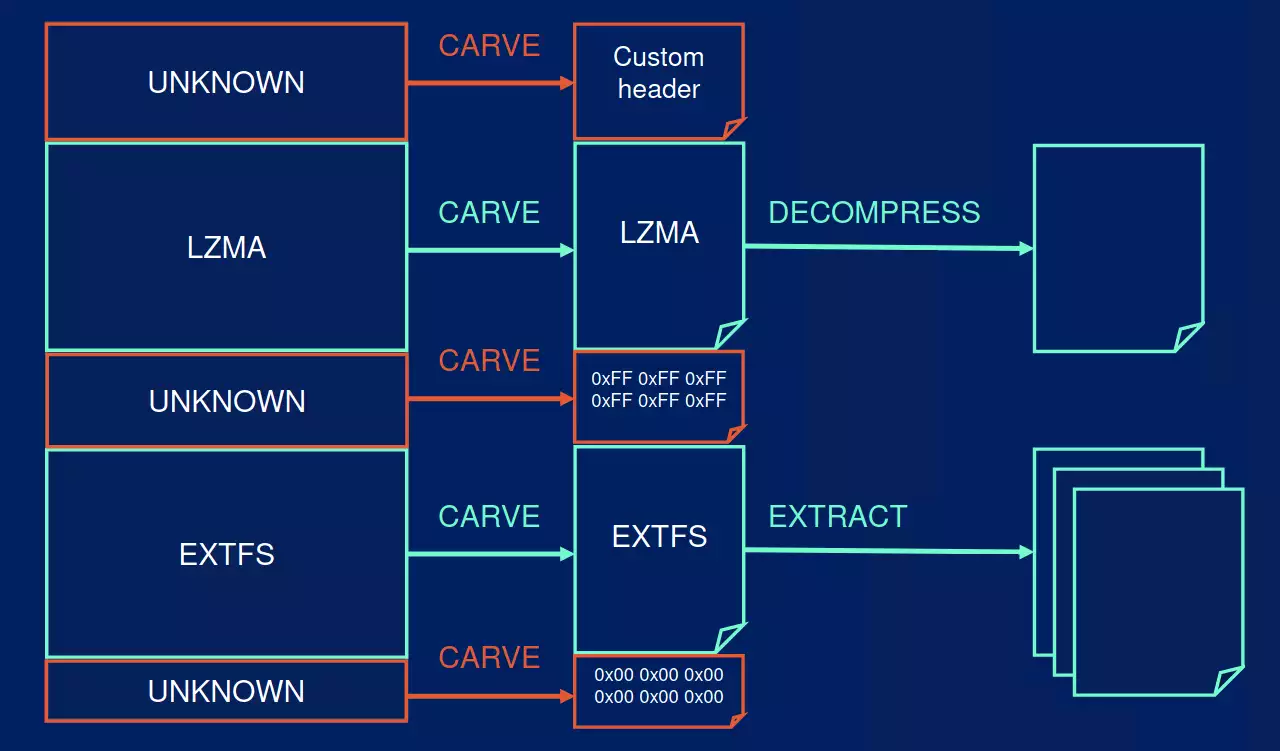
unblob identifies known and unknown chunks of data within a file:
-
known chunks are identified by finding the start offset using a search rule, and the end offset is computed based on the format standard. Unknown chunks represents unidentified chunks of data before, after, or between known chunks. Unknown chunks composed of known content (e.g., null padding,
0xFFpadding) are identified automatically and reported as such. -
unblob will carve out known chunks to disk and perform the extraction phase using the extractor assigned to a given handler. It will then walk the extracted content, looking for chunks in extracted files.
-
a report on metadata can be generated by unblob, providing detailed information about identified chunks (format, offsets, size, entropy) and their extracted content if available (ownership, permissions, timestamps, ...).
unblob also supports special formats where data is split across multiple files like multi-volume archives or data & meta-data formats:
-
Special DirectoryHandler is responsible to identify the files that make up a multi files set.
-
Identified MultiFile sets are not carved, but rather directly extracted using special DirectoryExtractor.
Used technologies¶
- unblob is written in Python.
- For quickly searching binary patterns in files, we use Hyperscan.
- For extracting recognized formats, we use all kinds of different Extractors.
- For ELF analysis, we are using LIEF with its Python bindings.
- For CPU-intensive tasks (e.g. entropy calculation), we use Rust to speed things up.
- For the pretty command line interface, we are using the Click library.
-
For structured logging, we are using the structlog library.
-
For development and testing tools, see the Development page.
License¶
unblob is licensed under the permissive MIT license, so you can use it without restrictions.